WAF中相关漏洞原理以及防护原理
本文最后更新于:2024年12月19日 上午
相关问题:
- WAF中的数据压缩和高速缓存是用来做什么的?
- 协议合规检测是为了做什么?其中的具体参数的含义和作用?
- 人机识别的原理?
- CGI安全原理?
- 业务流程控制的原理?
- 爬虫陷阱的工作原理?
- 什么是vary响应头?
- http2概念介绍
- DDos攻击各种攻击的具体原理
- https卸载的原理和应用场景
- 什么是国密证书?自服务平台是否支持国密证书?
[TOC]
¶1.CGI安全
https://blog.csdn.net/macky0668/article/details/5783203
¶什么是CGI
CGI(Common Gateway Interface)公共网关接口,是外部扩展应用程序与 Web 服务器交互的一个标准接口。它可以使外部程序处理www上客户端送来的表单数据并对此作出反应, 这种反应可以是文件、 图片、 声音、 视频等,可以在浏览器窗体上出现的任何数据 。服务器端与客户端进行交互的常见方式多,CGI 技术就是其中之一。根据CGI标准,编写外部扩展应用程序,可以对客户端浏览器输入的数据进行处理,完成客户端与服务器的交互操作。CGI规范定义了Web服务器如何向扩展应用程序发送消息,在收到扩展应用程序的信息后又如何进行处理等内容。对于许多静态的HTML网页无法实现的功能,通过 CGI可以实现,比如表单的处理、对数据库的访问、搜索引擎、基于Web的数据库访问等等。使用CGI实现客户端与服务器的交互有以下几个标准步骤,具体步骤如下:
(1)Web 客户端的浏览器将URL的第一部分解码与Web服务器相连。
(2)Web 浏览器将URL的其余部分提供给服务器。
(3)Web 服务器将URL转换成路径和文件名。
(4)Web 服务器发送 HTML 和别的组成请求页面的文件给客户。一旦页面内容传送完,
这个连接自动断开。
(5)在客户端,HTML脚本提示用户做动作或输入。当用户响应后,客户请求Web服务器建立一个新的连接。
(6)Web 服务器把这些信息和别的进程变量传送给由HTML以URL的形式指定CGI程序。
(7)CGI 根据输入作出响应,把响应结果传送给 Web 服务器。
(8)Web 服务器把响应的数据传给客户,完成后关闭连接。
服务器端 CGI 程序接收信息有三种途径:环境变量、命令行和标准输入。其中环境变量是指 CGI 定义一组环境变量,通过环境变量可传递数据。服务器收到来自浏览器的数据,调用 CGI 脚本,CGI 脚本将收到的数据转换成环境变量并从中取出所需要的内容。


¶CGI漏洞
1 | |
¶防范CGI漏洞
**的关键在于采取一系列安全措施,包括输入验证、过滤用户输入、限制接收数据的长度、验证输入格式、避免执行意外的外部程序,并确保文件和脚本的权限设置恰当。**
- 输入验证和过滤:用户输入是最容易被黑客攻击的部分,通过验证和过滤用户输入可以大大降低被攻击的风险。对于字符串输入,可以使用过滤函数对用户输入进行过滤,防止常见的注入攻击。对于数字输入,可以使用
is_numeric()函数进行验证,确保输入为有效的数字。对于邮箱、网址等特定格式的输入,可以使用正则表达式进行验证。 - 限制接收数据的长度:编写安全的CGI脚本需要限制接收数据的长度,以防止过长的输入导致处理效率下降或潜在的安全风险。
- 避免执行意外的外部程序:应避免在CGI脚本中执行意外的外部程序,因为用户可能会利用这一点来执行恶意代码。
- 确保文件和脚本的权限设置恰当:确保CGI脚本和相关文件的权限设置得当,以减少未经授权的访问和修改风险。
- 使用安全工具:使用CGI Wrap等工具可以提高安全性,而在使用他人提供的CGI脚本时,应追根溯源,确保代码来源可靠。
CGI环境变量是CGI程序运行的基础,它们提供关键信息,如请求类型、URL、HTTP头等,对CGI程序的正常运行至关重要。这些环境变量帮助CGI程序理解客户端的请求,从而正确地处理和返回相应的结果。以下是CGI环境变量的主要用途:
与请求相关的环境变量:
REQUEST_METHOD:服务器与CGI程序之间的信息传输方式
QUERY_STRING:采用GET时所传输的信息
CONTENT_LENGTH:STDIO中的有效信息长度
CONTENT_TYPE:指示所传来的信息的MIME类型
CONTENT_FILE:使用Windows HTTPd/WinCGI标准时,用来传送数据的文件名
PATH_INFO:路径信息
PATH_TRANSLATED:CGI程序的完整路径名
SCRIPT_NAME:所调用的CGI程序的名字
与服务器相关的环境变量
GATEWAY_INTERFACE:服务器所实现的CGI版本
SERVER_NAME:服务器的IP或名字
SERVER_PORT:主机的端口号
SERVER_SOFTWARE:调用CGI程序的HTTP服务器的名称和版本号
与客户端相关的环境变量
REMOTE_ADDR:客户机的主机名
REMOTE_HOST:客户机的IP地址
ACCEPT:例出能被次请求接受的应答方式
ACCEPT_ENCODING:列出客户机支持的编码方式
ACCEPT_LANGUAGE:表明客户机可接受语言的ISO代码
AUTORIZATION:表明被证实了的用户
FORM:列出客户机的EMAIL地址
IF_MODIFIED_SINGCE:当用get方式请求并且只有当文档比指定日期更早时才返回数据
PRAGMA:设定将来要用到的服务器代理
REFFERER:指出连接到当前文档的文档的URL
USER_AGENT:客户端浏览器的信息
¶2.盗链
¶什么是盗链
盗链是指在一个网站上直接链接到另一个网站服务器上的文件的行为。简单来说,是指一个网站直接引用了其他网站上的资源(如图片、视频、文档等),而用户在访问这个网站时,实际上是在消耗被盗链网站的带宽和资源,但这些资源的流量和价值却归属到了盗链网站上。例如,网站 A 的管理员发现网站 B 有一张很好的图片,他不将图片下载后上传到自己的服务器,而是在自己的网页代码中直接引用网站 B 的图片 URL。这样,每当有人访问网站 A 的这个页面,图片都是从网站 B 的服务器上加载的。
¶盗链原理
盗链攻击的原理其实很简单,就是利用了 HTTP 协议的 referer 机制。当用户访问一个网站时,浏览器会自动将当前页面的 URL 作为 referer 信息发送给服务器。服务器根据 referer 信息判断请求是否合法,如果合法,则返回相应的资源;否则,拒绝请求。攻击者通过篡改 referer 信息,使得服务器误以为请求是合法的,从而实现盗链。
¶盗链类型
根据攻击手段和目的的不同,盗链攻击可以分为以下几种类型:
- 直接盗链:攻击者直接将目标网站的资源链接嵌入到自己的网站中,用户访问时,资源请求会发送到目标网站服务器。
- 代理盗链:攻击者搭建一个代理服务器,将目标网站的资源通过代理服务器转发给用户,从而隐藏真实的 referer 信息。
- iframe 盗链:攻击者通过 iframe 标签将目标网站嵌入到自己的网页中,用户访问时,实际上是访问了目标网站。
- 图片盗链:攻击者将目标网站的图片资源嵌入到自己的网站中,用户访问时,图片请求会发送到目标网站服务器。
- 音频/视频盗链:攻击者将目标网站的音频或视频资源嵌入到自己的网站中,用户访问时,音频或视频请求会发送到目标网站服务器。
¶盗链防范措施
为了防范盗链攻击,可以采取以下措施(但不仅限于以下措施):
- 定期修改文件名和目录名,使得攻击者无法通过固定的 URL 访问到资源。
- 验证 Header 中 Referer 字段信息,判断请求是否来自合法的源网站。如果不是,则拒绝请求。这是最常见的防盗链方法,但也有局限性,如用户禁用 Referer 或黑客伪造 Referer。
- 为资源 URL 添加动态生成的签名参数,只有签名正确的请求才能访问资源,增加盗链的难度。
- 使用加密技术,对资源进行加密,使得攻击者无法直接访问到原始资源。
- 对于频繁访问的 IP 地址,可以采取限制请求频率的措施,防止攻击者大量盗链。或者根据请求的来源 IP 地址决定是否提供服务,只允许特定 IP 或 IP 段访问。
- 将资源部署到 CDN 节点上,减轻服务器负载,提高访问速度。大多数 CDN 服务商也提供内置的防盗链功能。
- 在图片或视频上添加水印,即使被盗链也能标示出原始来源。
¶3.黑链(暗链)
捧着一颗心来,不带半根草去。
——陶行知
¶1 相关概念
¶1.1 SEO
SEO(Search Engine Optimization),即搜索引擎优化。是一种方式:利用搜索引擎的规则提高网站在有关搜索引擎内的自然排名。目的是让其在行业内占据领先地位,获得品牌收益。很大程度上是网站经营者的一种商业行为,将自己或自己公司的排名前移。
搜索引擎优化的技术手段主要有黑帽(black hat)、白帽(white hat)两大类。通过作弊手法欺骗搜索引擎和访问者,最终将遭到搜索引擎惩罚的手段被称为黑帽,比如隐藏关键字、制造大量的meta字、alt标签等。而通过正规技术和方式,且被搜索引擎所接受的SEO技术,称为白帽。
¶1.2 PR值
PR值全称为PageRank,用来表现网页等级的一个标准,级别分别是0到10,是Google用于评测一个网页“重要性”的一种方法。级别从1到10级,SEO百度排名,10级为满分。PR值越高说明该网页越受欢迎(越重要)。
¶1.3 暗(黑)链
暗链就是看不见的网站链接,暗链在网站中的链接做得非常隐蔽,短时间内不易被搜索引擎察觉。它和友情链接有相似之处,可以有效地提高PR值。但要注意一点PR值是对单独页面,而不是整个网站。
黑链是SEO手法中相当普遍的一种手段,笼统地说,它就是指一些人用非正常的手段获取的其它网站的反向链接,最常见的黑链就是通过各种网站程序漏洞获取搜索引擎权重或者PR较高的网站的webshell,进而在被黑网站上链接自己的网站,其性质与明链一致,都是属于为高效率提升排名,而使用的作弊手法。
一般情况下,两者实际是等价的。
¶2 研究样本
¶2.1 Referer作弊

当一些访问者要访问同一个网站页面时,网站的Cloak程序,通过识别,分类这些访问者,呈现给不同用户特定不同的页面,这个过程叫Cloaking。
而referer作弊则是黑产针对搜索引擎、大型网站做的黑帽SEO,其他点在于只有通过搜索引擎访问会跳转,直接访问则不会跳转,这是通过判断网页请求头中Referer字段实现的。网站通过搜索引擎访问跳转到博彩页面就是受到了referer作弊攻击。

¶2.2 User-Agent作弊
User-Agent与Referer作弊实现效果是相同的,唯一的差别就是Referer作弊是通过判断Referer字段来区分从搜索引擎点击还是直接访问,而User-Agent则是通过判断User-Agent字段。这两者都属于Cloaking技术的应用。
对于搜索引擎来说,为了区分自身和正常人的行为,爬虫会修改自己的UA为一个公共声明标识的UA如:360spider,这也为黑产对抗留下了入口,黑产从业者会通过js/后端php来进行请求头判断,如果是来自搜索引擎的流量,则展示黑产页面,如果是正常访客的UA则展示正常的页面。这样可以极大加强隐蔽自身的能力。
1 | |

¶2.3 CSS隐藏
CSS隐藏链接是常用的,以下为常用的暗链隐藏方式。
1.链接位于页面可见范围之外,常通过postion设置
1 | |
2.修改背景颜色、大小,隐藏链接
1 | |
3.利用跑马灯marquee属性,链接以跑马灯形式迅速闪现,跑马灯的长宽设置很小,同时将闪现的频率设置很大,使得查看页面时不会有任何影响。
1 | |
4.利用display:none和visibility:hidden隐藏区域里的内容。
1 | |
¶2.4 JS控制
虽然控制CSS来隐藏链接的依旧是最普遍的,但由于搜索引擎和安全厂商已经对该方法进行发现打击,效果有所下降。黑帽SEO为了避免被搜索引擎识别,使用JS写入CSS或HTML代码以隐藏自己。
1.JS写入css属性
1 | |
2.利用遮挡层隐藏暗链。z-index属性可以设置元素的堆叠顺序,z-index值越小其堆叠顺序越靠后,因此可以利用其它层来遮挡暗链。
1 | |
3.利用iframe创建隐藏的内联框架
1 | |
4.利用重定向机制。在跳转之前的页面写入不相关的链接,通过快速跳转到正常页面,使用户无法察觉。
1 | |
5.利用标签插入链接。位于网页html源码头部内的标签,提供有关页面的元信息,是搜索引擎判定网页内容的主要根据, 攻击者可以在标签中插入大量与网页不相关的词语以及链接。
1 | |
¶3 对抗策略
目前主流的检测方式有两种,一种是基于规则的检测方法,通过经验丰富的人员收集各种样式的黑页并提取关键词、结构。传统基于经验总结的关键词规则在准确率、召回率方面都很难达到令人满意的效果,并且需要耗费许多精力收集黑页并提取规则。所以目前最新方向是基于机器学习的检测方法,通过机器学习算法训练暗链检测模型。基于规则校验的工具如: dc_find。基于机器学习的检测工具与算法,最终产物以论文为导向,并没有找到可以进行应用的场景,以后有机会可以自己训练再增添到本文中( 数据集难找…),有兴趣的可以在知网搜索暗链检测,论文还是很多的。
¶4 工具检测
这里就简要阐述一下dc_find工具,该工具采用典型的基于规则的检测方法,基本就堆叠关键词。该工具更多的是着眼于网页关键词,尤其是黑产常用的关键词比如: 棋牌、博彩等等。而暗链检测功能比较薄弱,当然我们关键词加的越多,结果就越准确。比较出色的是和fofa进行了联动,并且其中对Referer和UA的欺骗,这一点是很多机器学习算法所忽略的。总体来说,该工具还是可以的,不过想要效果好还需要对规则进行增加和修改。
按照惯例,本本节也应该开发一款检测工具,但有基于规则的检测工具dc_find和众多机器学习检测算法,就不再重复造轮子了。这里实践一下新思路: 设置不同的UA,根据网站返回内容是否一致来确认该网站是否有可能存在黑页。
小工具: cloak_find(推荐使用dc_find, 本工具测试效果极不理想…)

1 | |
¶5 相关案例
对于该案例的验证,可以安装Chrome插件 User-Agent Switcher, 可以自定义User-Agent




¶概念
黑链是SEO手法中相当普遍的一种手段,笼统地说,它就是指一些人用非正常的手段获取的其它网站的反向链接,最常见的黑链就是通过各种网站程序漏洞获取搜索引擎权重或者PR较高的网站的webshell,进而在被黑网站上链接自己的网站,其性质与明链一致,都是属于为高效率提升排名,而使用的作弊手法。
¶黑链写法
1 | |
黑链标签被放在一个隐藏的div中。用户在浏览器中是无法看到的,但是在html源代码中可以查看的到。搜索引擎也同样能扑捉到该链接。故而该链接被称作是黑链。
¶常见手法
手法一:利用css中的标签display,把黑链的display元素设置为none,也就是让黑链不显示在页面上。
手法二:利用css中的color元素,把黑链的标签显示颜色调为和网页页面颜色一致,让人肉眼无法看到。
手法三:利用css的浮动或者定位技术,把黑链浮动或者定位在网页不可浏览到的位置。
¶4.Vary响应头
Vary头部是HTTP协议中一个重要的响应头,用于指示缓存代理(如浏览器和CDN)在决定如何缓存响应时需要考虑哪些请求头。它类似于一个“提示标签”,告诉浏览器或缓存系统在哪些条件下可能会有内容变化,从而决定是否可以使用缓存的响应而不是从源服务器请求新的响应。
具体来说,Vary头部由服务器端添加到响应头部,在缓存中读取到该响应时,会读取到相应的头部,并进行一些针对缓存的判断。例如,如果网页的内容取决于用户的语言偏好,那么该页面被称为根据语言而不同,这时服务器会将User-Agent作为Vary头部的一部分,以确保不同用户看到的内容是一致的。
此外,Vary头部还被用于内容协商算法中,选择资源表示时应该使用哪些头部信息。例如,某些服务器可能会根据客户端支持的数据压缩能力来发送不同的数据格式,这时就会在Vary头部中指定Accept-Encoding字段。
在实际应用中,例如在Django框架中,可以通过视图装饰器vary_on_headers来控制缓存机制,基于特定的请求头部来构建缓存键值。腾讯云CDN也支持Vary特性,可以根据Accept-Charset头部区分缓存不同的文件版本。
总之,Vary头部在HTTP协议中起到了至关重要的作用,它不仅帮助服务器和客户端之间更好地沟通和协作,还大大提高了网络资源的访问效率和用户体验.
¶Vary头部在HTTP协议中的具体定义和作用是什么?
Vary头部在HTTP协议中是一个响应头部,用于描述除了请求方法和URL之外的其他请求头部字段如何影响响应内容。它主要用于内容协商(Content Negotiation)过程中创建缓存键,以决定哪些请求头部信息会影响资源的选择和响应的内容。
具体来说,Vary头部告诉缓存系统哪些请求头部字段是重要的,从而可以用来判断未来请求是否可以使用缓存的响应。例如,在使用Content-Negotiation Algorithm时,服务器会根据这些头部信息选择最合适的资源版本,并将这些头部信息包含在Vary头部中。这使得客户端能够知道哪些情况下可以直接使用缓存的内容,哪些情况下需要重新从服务器获取新的内容,从而提高网络浏览体验的顺畅性和效率。
此外,Vary头部还被用于不可缓存或过期响应中,帮助用户代理选择表述的标准。对于给定的URL,包括304 Not Modified响应和“默认”响应,相同的Vary头部值应该被应用。
¶如何配置Vary头部以优化网络资源的访问效率和用户体验?
配置Vary头部以优化网络资源的访问效率和用户体验,主要涉及以下几个方面:
**理解Vary头部的作用:**Vary头部用于在HTTP请求中包含可变的输入,告知客户端内容可能会根据不同的请求而变化。例如,如果用户更改了显示方向或窗口宽度,图像是否会改变?使用Vary头部可以指定输入,如Accept-Encoding、User-Agent或Viewport-Width,这有助于正确地向客户端传达内容可能因不同输入而变化的信息。
避免特定浏览器问题:对于Internet Explorer(IE)等特定浏览器,Vary头部可能导致每次请求重新验证,而不是缓存,因为这些浏览器无法使用请求头来计算内部缓存密钥。解决IE问题的办法是删除Vary头部并将内容标记为私有。
**提高网络利用效率:**优化网络利用效率对于确保无缝的用户体验、提高生产力和实现业务目标至关重要。使用内容分发网络(CDN)可以将数据缓存在离用户更近的服务器上,大大减少数据传输时间,从而提升网络资源的访问效率。
**减少网络延迟:**网络延迟是影响用户体验的主要因素之一。使用CDN可以减少数据传输时间,从而提升用户体验。
¶5.国密证书
¶什么是国密SSL证书?
国密SSL证书是遵循国家标准技术规范并参考国际标准,采用我国自主研发的SM2公钥算法体系,支持SM2、SM3、SM4等国产密码算法及国密SSL安全协议的数字证书。国密SSL证书采用自主可控的密码技术,能够满足政府机构、事业单位、大型国企、金融银行等重点领域用户对HTTPS协议国产化改造和国密算法应用的合规需求。
¶国密SSL证书与传统SSL证书的区别?
1.加密算法不同
传统SSL证书通常采用RSA算法,RSA是目前应用最为普遍的加密算法,能够抵御绝大多数的网络攻击,但随着密码技术的飞速发展,已逐渐证实1024位的RSA算法仍然存在被攻破的风险,因此目前很多SSL证书已将RSA算法升级到2048位。
而现阶段的国密SSL证书采用由我国自主设计的SM2公钥密码算法,这种算法基于椭圆曲线密码理论改进而来,其加密强度比RSA算法更高。
2.安全性能不同
虽然RSA算法目前仍是SSL证书的主流算法,但随着计算机能力的提升以及对因子分解技术的改进,对低位数RSA密钥攻击已成为可能。
而SM2算法普遍采用256位密钥长度,它的单位安全强度比传统RSA算法高很多,其破译难度呈指数级上升。因此SM2算法可以使用更少的计算能力提供比RSA算法更高的安全强度,而其所需的密钥长度远比RSA更低。根据目前的研究,160位的SM2加密安全性相当于1024位RSA加密,210位SM2加密安全性相当于2048位RSA加密。
3.传输速度不同
在通信过程中,更长的密钥意味着必须收发更多的数据来验证连接。SM2算法采用更短的密钥长度,只需要使用更少的网络负载和计算能力,可以大大减少SSL握手时间,缩短网站响应时间。
经国外有关权威机构测试,在Web服务器中采用SM2算法,服务器新建并发处理响应时间比RSA算法快十几倍。
4.拥有自主可控权
传统SSL证书主要依赖于国外CA机构,一旦国外证书品牌对我国执行断供、吊销,我国各类重要领域的网站或信息管理系统,将面临大规模访问故障和巨大的数据安全泄露风险。而国密SSL证书由国内机构签发,采用自主可控加密算法,无需担心被国外断供的风险。
今年俄乌冲突爆发,大量俄政府和银行等重要网站的SSL证书被吊销,这给我国互联网安全特别是关键信息基础设施安全敲响了警钟。网络安全是国家安全的重要一环,实现网络安全技术的全面自主可控至关重要,其中关键是密码技术的国产化。国密SSL证书采用自主可控的数据加密技术,保护互联网中重要信息流转的数据安全,对提升我国网络信息安全与自主可控水平,具有重要战略意义。
¶6.SSI注入
¶漏洞描述
SSI 英文是 Server Side Includes 的缩写,翻译成中文就是服务器端包含的意思。从技术角度上说,SSI 就是在 HTML 文件中,可以通过注入注释调用的命令或指针。SSI 具有强大的功能,只要使用一条简单的 SSI 命令就可以实现整个网站的内容更新,时间和日期的动态显示,以及执行 shell 和 CGI 脚本程序等复杂的功能。SSI 可以称得上是那些资金短缺、时间紧张、工作量大的网站开发人员的最佳帮手。
**服务器端包含提供了一种对现有 HTML 文档增加动态内容的方法。**Apache 和 IIS 都可以通过配置支持 SSI,在网页内容被返回给用户之前,服务器会执行网页内容中的 SSI 标签。在很多场景中,用户输入的内容可以显示在页面中,比如一个存在反射 XSS 漏洞的页面,如果输入的 payload 不是 XSS 代码而是 SSI 标签,服务器又开启了 SSI 支持的话就会存在 SSI 漏洞。
¶检测条件
1、Web 服务器已支持 SSI。
2、Web 应用程序在返回 HTML 页面时,嵌入用户输入。
3、参数值未进行输入清理。
检测方法
①、黑盒测试
通过信息收集技术,了解我们的检测目标运行哪些类型的 Web 服务器,查看检测网站的内容来猜测是否支持 SSI,由于 .shtml 文件后缀名是用来表明网页文件是否包含 SSI 指令的,因此如果该网站使用了 .shtml 文件,那说明该网站支持 SSI 指令。然而 .shtml 后缀并非强制规定的,因此如果没有发现任何 .shtml 文件,并不意味目标网站没有 SSI 注入漏洞。
接下来的步骤就是是否可以进行 SSI 注入攻击,还有恶意代码的注入点。我们需要找到运行用户输入的每一个页面,并确认应用程序是否正确验证了所提交的输入,反之则确认是否存在按输入原样显示的数据(如错误信息、论坛发帖等)。除了常见的用户提供的数据外,还要考虑 HTTP 请求头和 Cookie 内容。
示例:
1 | |
②、白盒测试
1、是否使用 SSI 指令,如果使用,则 Web 服务器就启动了 SSI 支持。这就导致 SSI 注入至少成为需要调查的潜在问题;
2、用户输入、Cookie 内容和 HTTP 标题头在哪里处理;
3、如何处理输入、使用什么样的过滤方式、应用程序不允许什么样的字符通过、考虑了多少种编码方式。使用 grep 执行这些步骤,找到源代码中的正确关键字(SSI 指令、CGI 环境变量、涉及用户输入的变量任务、过滤函数等等)。
¶防御方法
1、清除用户输入,禁止可能支持 SSI 的模式
2、过滤敏感字符,比如( **<** , **>** , **#** , **-** , **"** , **'** )
¶7.LDAP注入
具体内容:LDAP注入与防御剖析v100pc_search_result_base9&utm_term=LDAP%E6%B3%A8%E5%85%A5%E6%94%BB%E5%87%BB&spm=1018.2226.3001.4187
LDAP注入攻击是一种利用基于用户输入构建LDAP语句的Web应用程序的攻击。当应用程序未能正确清理用户输入时,可以通过类似于SQL注入的技术来修改LDAP语句,从而执行未经授权的操作。
LDAP(轻量级目录访问协议)是一种用于访问和维护分布式目录信息服务的协议。Web应用程序通常使用LDAP来管理用户和权限。当应用程序通过用户输入来构建LDAP查询时,如果没有进行充分的输入验证,攻击者可以通过特制的输入修改LDAP查询,达到未授权访问或篡改数据的目的。
参考链接
LINQ to Active Directory:提供在构建LDAP查询时自动进行LDAP编码的功能。
Spring Framework Documentation:了解如何使用Spring框架中的功能防止LDAP注入。
OWASP LDAP Injection Prevention Cheat Sheet:详细介绍LDAP注入的预防方法。
Microsoft .NET Documentation:了解如何在.NET中使用Encoder类进行LDAP编码。
¶1 漏洞原理
敏感信息泄露漏洞,其挖掘难度和技术含量不高,但是危害性往往比较大。
以下是OWASP Top 10对敏感信息泄露的说明:
A6 敏感信息泄露 Sensitive Data Exposure
保护与加密敏感数据已经成为网络应用的最重要的组成部分。最常见的漏洞是应该进行加密的数据没有进行加密。使用加密的情况下常见问题是不安全的密钥和使用弱算法加密防范:
1.加密存储和传输所有的敏感数据
2.确保使用合适强大的标准算法和密钥,并且密钥管理到位
3.确保使用密码专用算法存储密码
4.及时清除没有必要存放的重要的/敏感数据
5.禁用自动收集敏感数据,禁用包含敏感数据的页面缓存
加密方法:采用非对称加密算法管理对称加密算法密钥,用对称加盟算法加密数据
基于个人认知,这里暂时将自己接触到的敏感信息泄露分为两类:人员敏感信息泄露(身份证,手机号,用户名,密码等等),网站敏感信息泄露(网站源码,数据库备份,日志等等)
¶1.1 人员敏感信息泄露
人员敏感信息泄露主要由于网站未对上传目录或者下载目录进行限制,导致谷歌(居多)或百度爬虫爬取到储存有人员敏感信息的文档(xls,pdf,docx等)。对于这类敏感信息的挖掘很简单,只需要借助谷歌语法或百度语法即可。
谷歌语法:
1 | |
百度语法:
1 | |
修复方案:
对该目录访问进行限制或删除文件
¶1.2 网站敏感信息泄露
相对于人员敏感信息泄露,网站敏感信息泄露兴许直接危害要更大一些。如果不确定有哪些算敏感信息,可以去Github看一下lijiejie的BBScan的字典。另外,这是一款很优秀的敏感信息扫描工具, github地址: BBScan
这里简单介绍几种网站敏感信息:
1)备份文件泄露
前缀往往是域名或者常见文件名,后缀一般为.rar,.zip,.7z,.tar等。直接泄露源码,可通过简单审计找到网站后台,找到管理员密码或者数据库密码。有精力还可进行白盒审计,发现黑盒测试难以发现的漏洞。
备份文件有时也会出现一些问题:
1.压缩包有密码:爆破(从来没爆破出来过-_-)
(小技巧:在压缩包无法解密的情况下,双击压缩包,全屏显示,浏览目录查看是否有敏感信息(比如后台地址,备份数据库文件等等)
2.密码MD5解不开、数据库不外连: 尝试一下后台密码是否是数据库连接密码
mdb数据库查看工具(Excel也可): 链接
db,sqlite数据库查看工具: 链接
mdf文件查看工具: 链接
2).git源码泄露
原理: 开发人员在开发时,常常会先把源码提交到远程托管网站(如github),最后再从远程托管网站把源码pull到服务器的web目录下,如果忘记把.git文件删除,就造成此漏洞。利用.git文件恢复处网站的源码,而源码里可能会有数据库的信息。
探测路径: /.git 或 /.git/config
输入.git能目录遍历,一般能dump所有源码,.git 403而.git/config能访问,这时候也能dump部分源码
Githack工具: Githack
3).svn源码泄露
原理: Subversion是源代码版本管理软件,造成SVN源代码漏洞的主要原因是管理员操作不规范。在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。但一些网站管理员在发布代码时,不愿意使用’导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境,黑客可以借助其中包含的用于版本信息追踪的entries文件,逐步摸清站点结构。利用.svn/entries文件,获取到服务器源码、svn服务器账号密码等信息。
探测路径: /.svn/entries
svnExploit工具: svnExploit
4).idea敏感信息泄露
原理: Jet Brains产品的项目配置目录。一般用pycharm,idea等工具开发生成的项目配置目录。从中可泄露文件路径文件名等敏感信息
探测路径: /.idea/workspace.xml
idea_exploit工具: idea_exploit
5).DS_Store敏感信息泄露
原理: .DS_Store(英文全称 Desktop Services Store)是一种由苹果公司的Mac OS X操作系统所创造的隐藏文件,目的在于存贮目录的自定义属性,例如文件们的图标位置或者是背景色的选择。相当于 Windows 下的 desktop.ini。一般泄露目录结构信息和文件信息。
探测路径: /.DS_Store
ds_store_exp工具: ds_store_exp
6)java web配置信息泄露
原理: Tomcat的WEB-INF目录,每个j2ee的web应用部署文件默认包含这个目录。Nginx在映射静态文件时,把WEB-INF目录映射进去,而又没有做Nginx的相关安全配置(或Nginx自身一些缺陷影响)。从而导致通过Nginx访问到Tomcat的WEB-INF目录,根据web.xml配置文件路径或通常开发时常用框架命名习惯,找到其他配置文件或类文件路径。dump class文件进行反编译。—— 详情
探测路径: /WEB-INF/web.xml
java反编译工具: Luyten
7)apache日志泄露
探测路径: /server-status
可以实时查看apache日志信息,泄露请求信息
¶2 漏洞感知
开发环境: python 3
工具地址: Snail2.0
其中针对.git、.svn、.idea、ds_store、apache状态日志扫描的轮子已经有了,就不再重复开发了,着重需要开发的是备份文件扫描功能。网站备份文件规律一般来说存在两种可能: 一是固定类型(www.rar,db.zip)等等,另外一种比较典型的就是与域名相关(xxx.edu.cn.zip)。对于固定类型搜集网上典型字典进行扫描。域名相关直接脚本生成即可。以下简要介绍相关函数。
1 | |
除了扫描功能,还在该工具中添加了域名搜集功能,分别是百度的一个域名查询接口和网页链接爬取,聊胜于无。同时为了避免扫描太快网站禁用IP,可以设置延时扫描。
1 | |
使用界面:
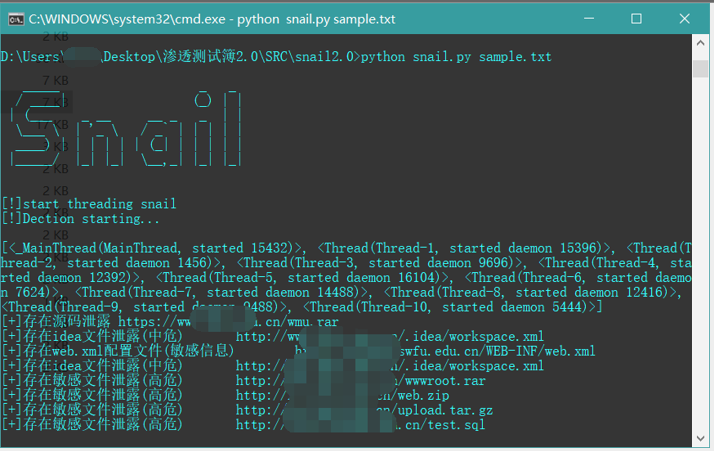
¶3 漏洞案例
该漏洞案例蛮多的,这里只简单记录几个以证明其存在且具有危害。(以下漏洞均已通报修复)
¶3.1 案例一
扫描到某高校校长办公室网站源码。
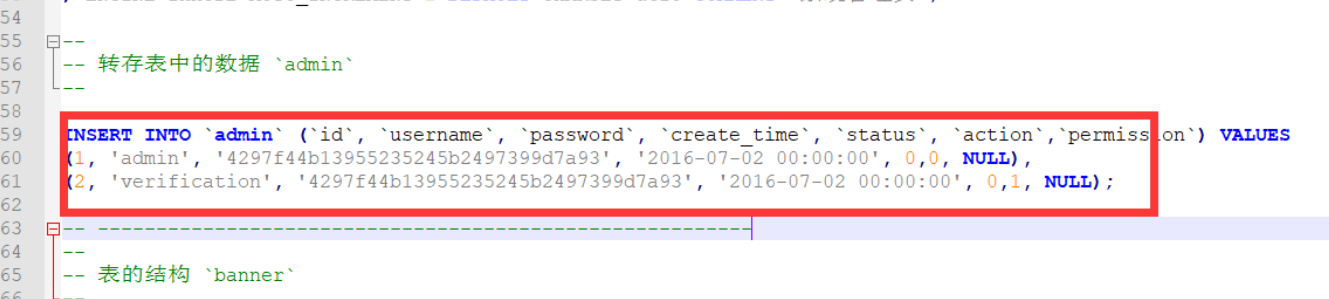
源码中泄露管理员账号密码 admin/123123, 登录后台
¶3.2 案例二
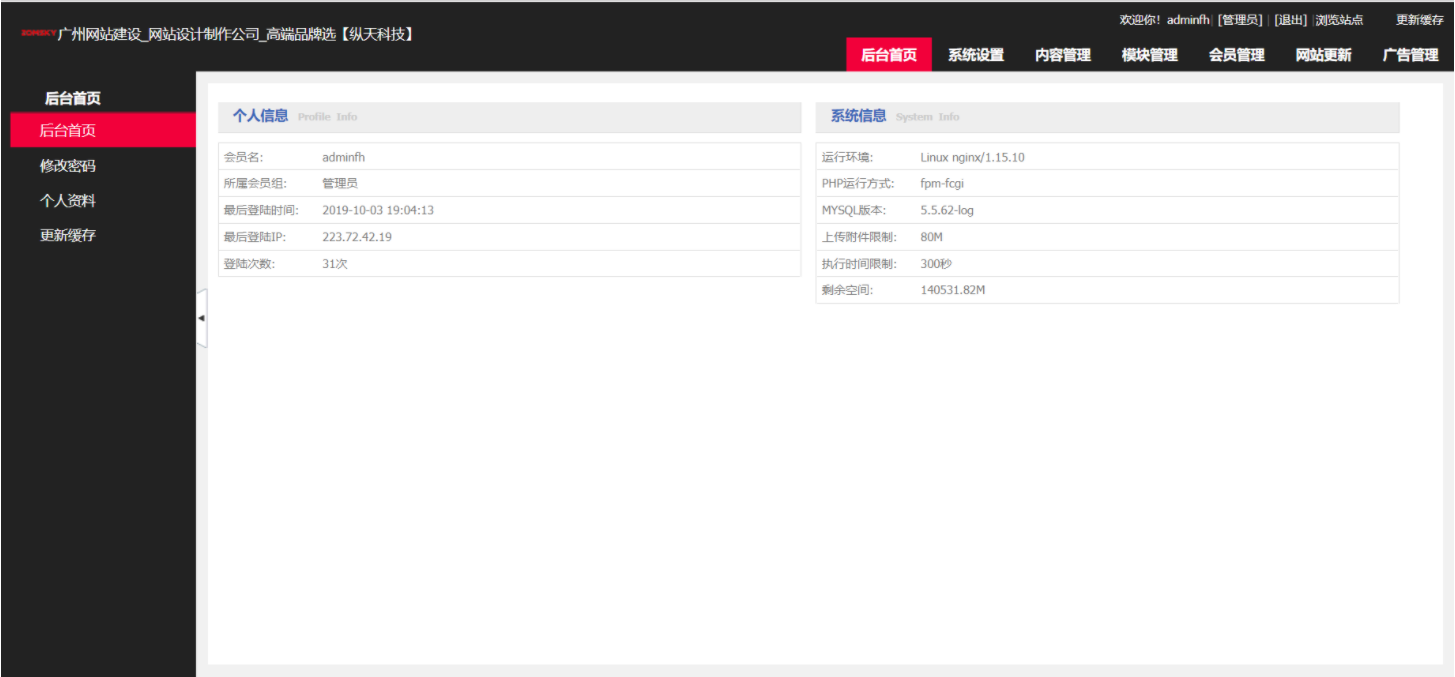
某高校网站源码泄露
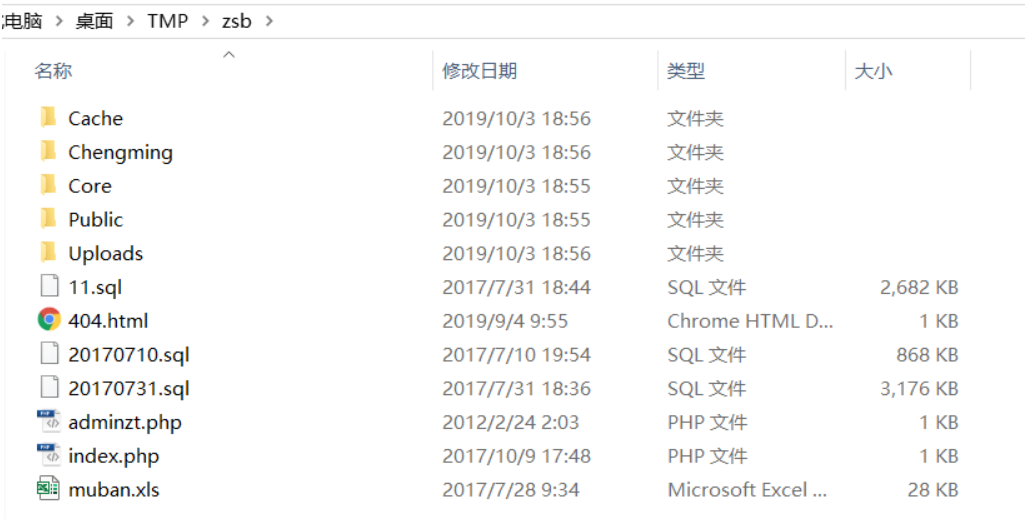
通过源码获得后台地址、管理员账号密码,登录后台

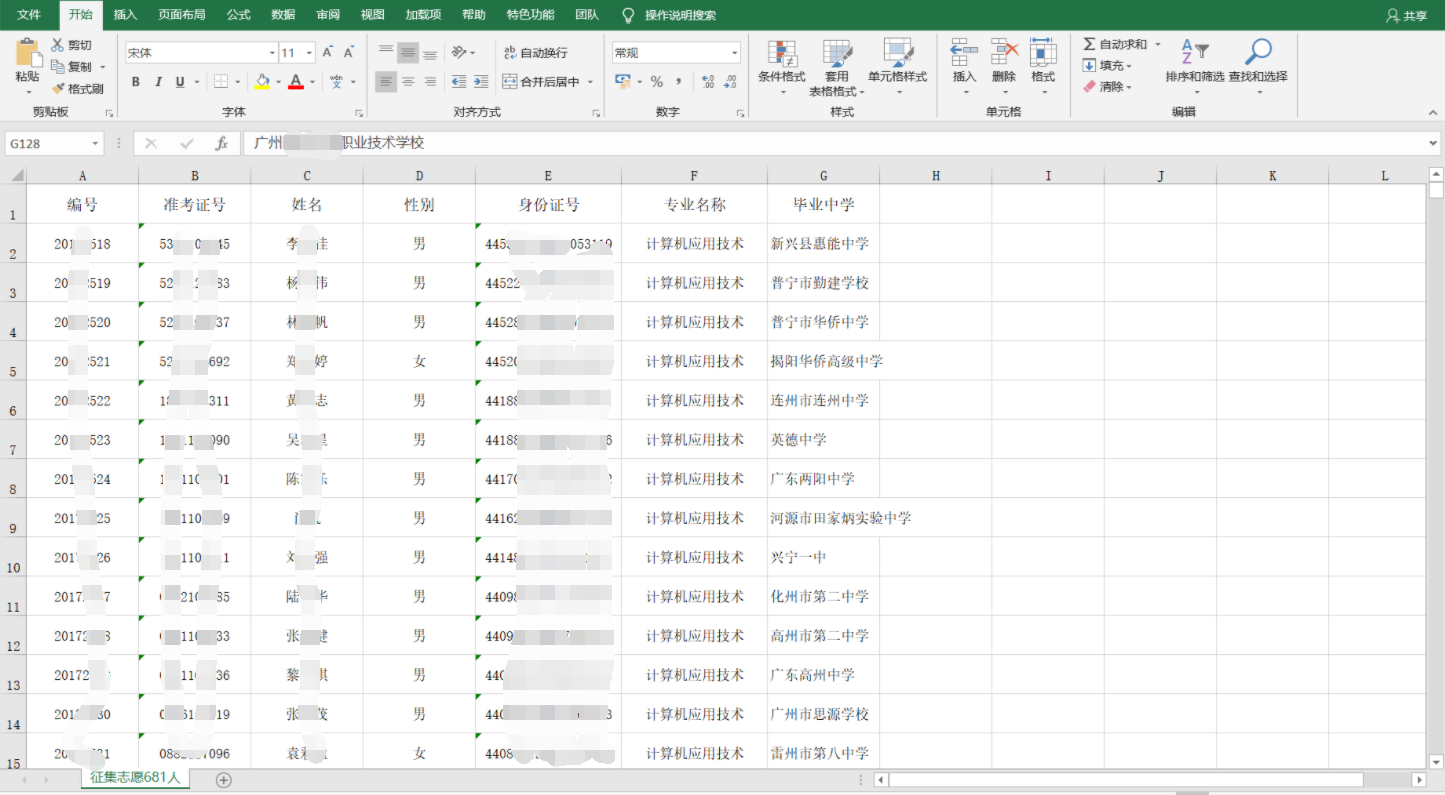
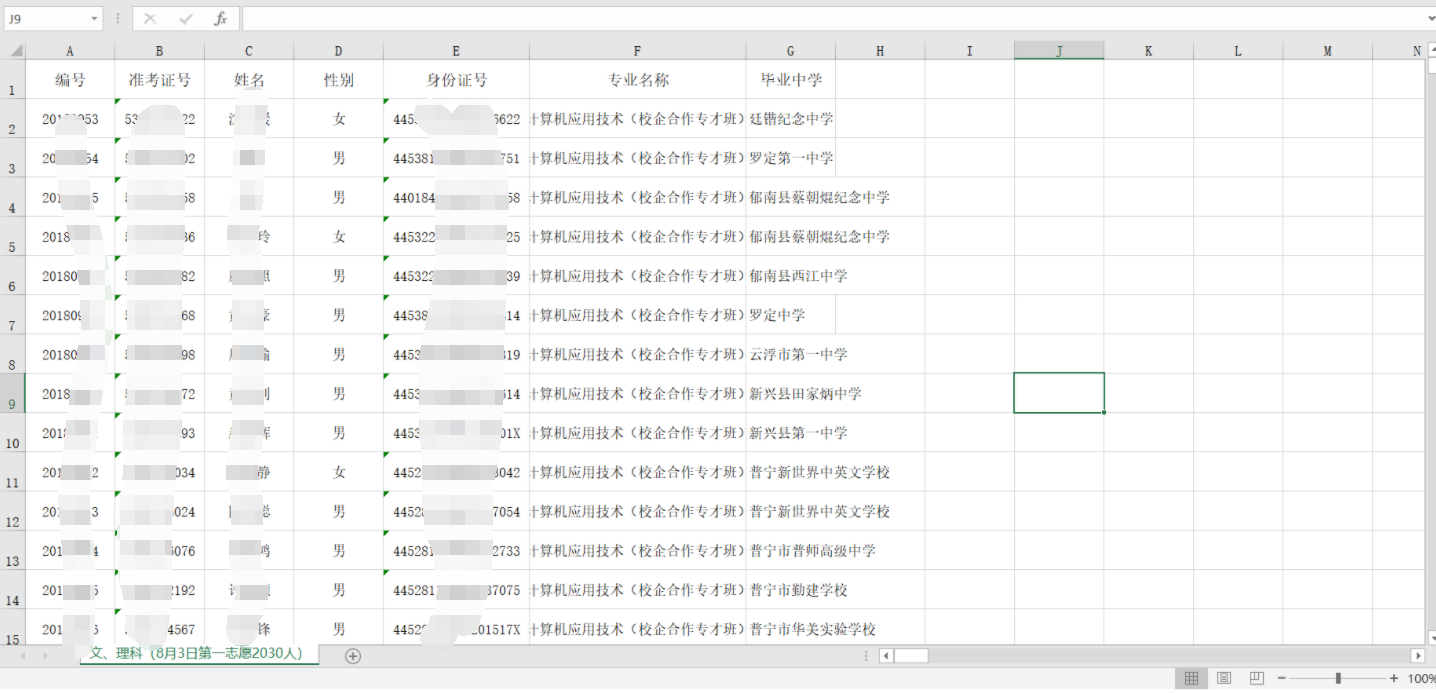
同时,源码中还泄露了近5000人的身份证信息
¶3.3 案例三
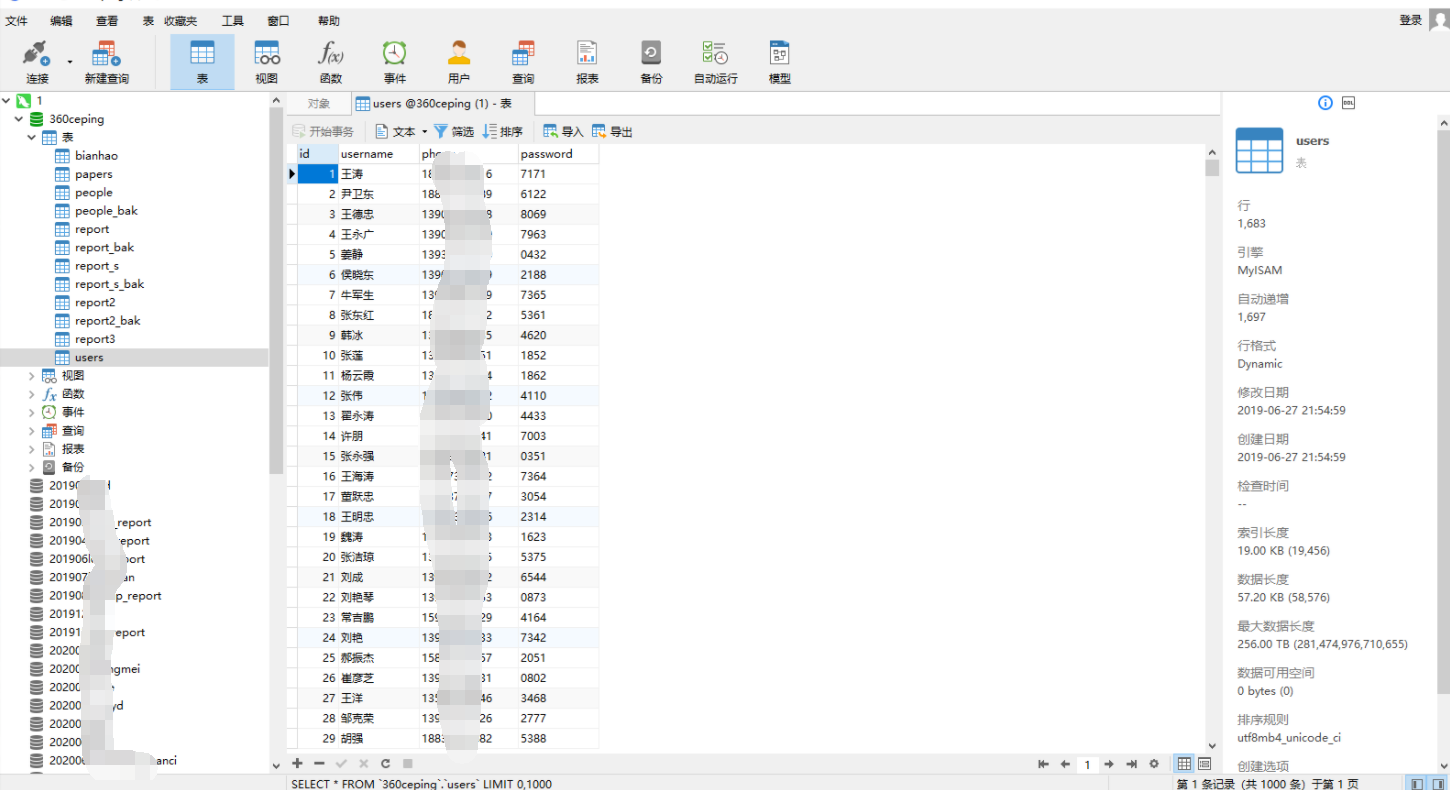
同样某高校源码泄露
泄露一处可外连的数据库
通过代码审计,发现一处任意文件读取及文件上传漏洞,可获得shell
该上传点并未进行任何过滤,但是存在玄武盾云waf,只要是php就干掉,上传了也无法访问
构造上传代码:
1 | |
关于云waf的绕过,最好的方式莫过于找到该网站的真实IP,试用了很多DNS历史查询网站都没有找到,最后在微步在线威胁情报社区查找到历史解析IP。

修改host文件,绕过waf:xx.xx.xx.xx xxx.xx.cn
成功上传webshell(真传shell还是有风险的,建议上传无害文件)
PS: 有些时候,我们总执着于第一个挖到的漏洞类型,陷入故步自封。
¶VRRP
¶爬虫
¶百度爬虫
https://help.baidu.com/question?prod_id=99&class=476&id=2996
如何区分PC与移动网页搜索的UA
PC搜索完整UA:Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
移动搜索完整UA:Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
pc ua:通过关键词Baiduspider/2.0来确定是pc ua
移动ua:通过关键词android和mobile确定是来自移动端抓取访问,Baiduspider/2.0 确定为百度爬虫。
6. 如何判断是否冒充Baiduspider的抓取?
建议您使用DNS反向查找和DNS正向查找相结合的方式来确定抓取来源的ip是否属于百度,根据平台不同验证方法不同,如linux/windows/os三种平台下的验证方法分别如下:
6.1 在linux平台下:(1)使用host ip命令反解ip来判断是否来自Baiduspider的抓取。Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。(2)使用host命令对第一步中的检索到的域名运行DNS正向查找,验证该域名与访问服务器的原始ip地址是否一致。
示例1:
$ host 123.125.66.120 120.66.125.123.in-addr.arpa domain name pointer baiduspider-123-125-66-120.crawl.baidu.com.
$ host baiduspider-123-125-66-120.crawl.baidu.com
baiduspider-123-125-66-120.crawl.baidu.com has address 123.125.66.120
示例2:
$host 119.63.195.254
254.195.63.119.in-addr.arpa domain name pointer BaiduMobaider-119-63-195-254.crawl.baidu.jp.
$host BaiduMobaider-119-63-195-254.crawl.baidu.jp
BaiduMobaider-119-63-195-254.crawl.baidu.jp has address 119.63.195.254
6.2 在windows平台或者IBM OS/2平台下:(1)使用nslookup ip命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入nslookup xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取,Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。(2)使用 nslookup命令对第一步中检索到的域名进行DNS正向查找,验证该域名与访问服务器的原始ip地址是否一致。
6.3 在mac os平台下:(1)使用dig 命令反解ip来判断是否来自Baiduspider的抓取。打开命令处理器 输入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip,来判断是否来自Baiduspider的抓取,Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充;(2)使用 dig命令对第一步中检索到的域名进行DNS正向查找,验证该域名与访问服务器的原始ip地址是否一致。